📌 DB Replication의 개념에 대해 알아보자!!
주제: DB Replication 이게 뭔가요?
Replication은 복제를 뜻한다.
당연히 DB를 복제하여 사용한다는 것과 관련있다.
그렇다면 과연 DB를 복제하여 무슨 용도로 어떻게 활용할까?
왜 복제를 하는데요?
대표적으로 다음과 같은 상황이 있다.
개발자A의 서비스가 알 수 없는 이유로 DB 서버가 응답하지 않았다. 심지어 재가동을 하여도 상황이 동일했다.
어느 날, 개발자B가 서비스하는 웹에서 이벤트를 오픈하게 되는데 예상보다 많은 트래픽으로 하나의 DB로는 트래픽을 감당할 수 없었다.
> 개발자A와 B는 원할한 서비스를 제공하기 힘들었다. 개발자A와 B가 이 상황을 극복하려면 어떤 조치를 취해야 할까?
A의 경우는 예상치 못한 오류로 인해 DB 서버에 문제가 발생했다.
오류의 원인을 분석하는 것도 중요하지만, 개발자에게 오류는 예측할 수 없는 범위에서 일어나는 경우가 많다.
때문에, DB 서버가 응답하지 않을 경우의 해결책이 필요했다.
B의 경우는 트래픽 자체가 현재 DB로는 감당할 수 없는 양이기 때문에 DB서버의 스팩을 높여야한다.
혹은 어떤 효율적인 구조 변경을 통해 많은 트래픽을 처리할 수 있는 방법을 고안해야 했다.
이러한 상황에서 개발자 A와 B에게 필요한 것은 기존 DB서버를 복제하여 사용하는 DB Replication 이다.
DB Replication 방식
기본적인 DB Replication 방식의 서버 종류
- Source: 원본 데이터를 가진 DB 서버
- Replica: 복제된 데이터를 가진 DB 서버
1. 개발자A의 문제를 해결할 Source-Replica 구조
개발자 A는 Source 서버와 Replica 서버를 구축해둔 경우 다음과 같이 문제점을 해결할 수 있다.
Source 서버의 데이터 변경이 일어날 경우, Replica 서버에도 동일하게 반영됨.
만약, Source 서버에 문제가 발생한 경우, Replica 서버를 Source 서버로 승격시켜 사용함.
2. 개발자B의 문제를 해결할 write-read DB 분리
개발자 B는 write DB와 read DB로 분리하여 처리할 경우 트래픽을 보다 안정적으로 분리할 수 있다.
Source 서버를 write DB로 설정하고, Replica 서버를 읽기 전용인 read DB로 설정하여 트래픽을 분리함.
복제가 일어나는 방식
복제는 바이너리 로그(Binary Log)를 기반으로 복제가 일어난다.
바이너리 로그: 모든 변경사항(이벤트)이 로그 파일에 순서대로 기록되는 것.
간단하게 정리하자면,
- Source 서버에 작업이 일어남
- 바이너리 로그에 이벤트가 기록됨
- 기록된 이벤트를 Replica 서버가 자신의 로컬에 저장함
- 로그를 읽어서 Replica 서버에 적용함
복제의 타입
Replica 서버는 바이너리 로그를 식별하는 방법에 따라 두 가지 타입이 존재한다.
1. 바이너리 로그 파일 위치 기반 복제
소스 서버의 바이너리 로그에 파일명과 Offset을 사용하여 식별함. 그러나, 소스 서버에서만 유용한 식별 방식이다. 이러한 단점은 아래와 같은 상황을 야기한다.
- 기존 소스 서버A에 문제가 생겨서 레플리카 서버B를 승격시킨다.
- 파일 위치 기반 복제는 기존 소스 서버의 위치에만 유효했었다.
- 나머지 레플리카 서버 C, D, E는 로그를 봐도 알 수가 없다.
2. 글로벌 트랜잭션 ID(GTID) 기반 복제
복제에 참여한 모든 DB들이 고유한 식별값을 가진다.
이 값은 모두 동일하기 때문에 다른 레플리카 서버가 승격되어도 로그를 읽어오는데 문제가 안된다.
복제 데이터의 저장방식(포맷)
포맷 방식은 세 가지가 존재한다.
- Statement 기반 방식 > SQL문이 저장
- Row 기반 방식 > 변경된 데이터가 저장
- Mixed 기반 방식 > 1, 2의 합성 방식
1. Statement 기반 방식
말 그대로 실행된 SQL문을 로그에 저장하는 방식이다.
장점
여러 개의 데이터를 수정하는 쿼리여도 SQL문 하나만 기록된다. > 저장 공간에 대한 부담 감소, 빠른 처리 가능
단점
비확정적 쿼리의 경우 데이터 동기화 문제 발생
트랜잭션 내에서 쿼리가 실행되는 시점마다 데이터 스냅샷이 달라질 수 있음
즉, 저장 공간의 감소에 대한 이점이 있지만, Statement 기반 방식은 일관성을 완벽히 보장할 수 없다.
2. Row 기반 방식
변경 값 자체(테이블)를 바이너리 로그에 저장한다.
장점
트랜잭션 격리 수준에 관계 없이 사용 가능
단점
데이터를 많이 변경하는 SQL문인 경우, 모든 데이터를 다 저장하다 보니, 로그 파일의 크기가 커짐.
어떤 쿼리들이 넘어왔는지 확인할 수 없다.
즉, 일관적으로 저장은 가능하나, 저장 공간의 측면에서 단점이 있음.
3. Mixed 기반 방식
일반적인 쿼리는 SQL문을 저장하고, 비확정적 쿼리의 경우는 Row 포맷으로 저장한다.
이를 통해 각 방식의 장단점을 보완할 수 있다.
복제 동기화 방식
1. 비동기 복제
소스 서버가 레플리카 서버에서 변경 이벤트가 정상적으로 전달 됐는지 확인하지 않는다.
과정
- 데이터 변경 요청이 들어온다.
- 바이너리 로그에 이벤트를 먼저 작성한다.
- 변경 요청을 소스 서버의 스토리지 엔진에 커밋한다.
- 변경 이벤트를 레플리카 서버로 전송한다.
특징
빠르게 처리되지만 동기화가 보장되지 않는다.
2. 반동기 복제
소스 서버는 레플리카 서버가 소스 서버로부터 전달 받은 반경 이벤트를 릴레이 로그에 기록 후 응답을 보내면 그때 트랜잭션을 완전히 커밋한다.
과정
- 데이터 변경 요청이 들어온다.
- 바이너리 로그에 이벤트를 먼저 작성한다.
- 변경 이벤트를 레플리카 서버로 전송한다.
- 레플리카 서버가 변경 이벤트를 잘 수신했다는 응답을 보낸다. (이것이 레플리카 서버에 적용되었다는 보장은 없다)
- 변경 요청을 소스 서버의 스토리지 엔진에 커밋한다.
소스서버와 레플리카 서버를 구성하는 방법
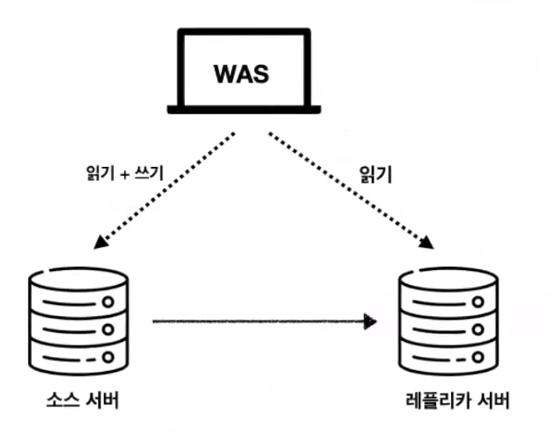
1. 싱글 레플리카
구성: 소스 서버 1대, 레플리카 서버 1대
각 서버의 용도
소스 서버: 읽기 + 쓰기 역할
레플리카 서버: 읽기 전용, 예비/백업용으로 활용
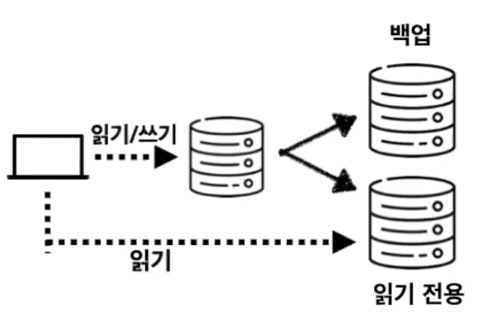
2. 멀티 레플리카
구성: 소스 서버 1대, 레플리카 서버 2대
각 서버의 용도
소스 서버: 읽기 + 쓰기 역할
레플리카 서버1: 쿼리 부하 분산(읽기 전용) 레플리카 서버2: 백업용
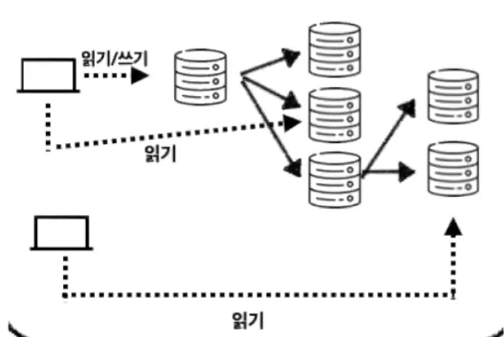
3. 체인 복제
구성: 소스 서버 1대, 레플리카 서버 n대
사용이유: 소스 서버에 연결된 레플리카 서버가 많아질수록 소스 서버의 복제부하가 많아진다. 따라서 또 다른 레플리카 서버를 추가 레플리카 서버에 연결하여 복제 부하를 나눠준다.
각 서버의 용도
소스 서버: 읽기 + 쓰기 역할
레플리카 서버1~n: 쿼리 부하 분산(읽기 전용) 복제 부하를 나누는 레플리카 서버: 새로운 레플리카 서버에 복제하는 역할을 하는 레플리카 서버
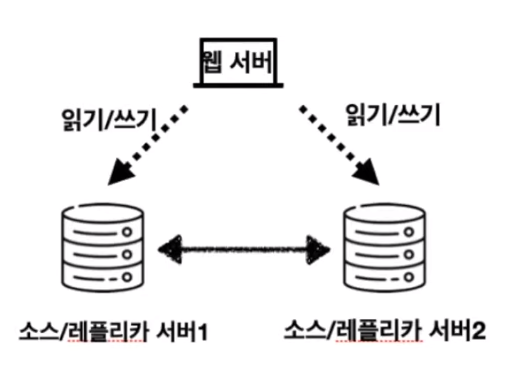
4. 듀얼 소스 복제
구성: 소스/레플리카 서버 2대
기존에는 소스 서버와 레플리카 서버를 구별했다면, 해당 방식은 두 서버의 권한을 동등하게 부여하여 읽기와 쓰기가 가능하다.
서로 동일한 데이터를 가지며, 트랜젝션 충돌이 일어날 경우, 롤백 또는 복제 멈춤 현상이 일어나므로 잘 사용하지 않는다.
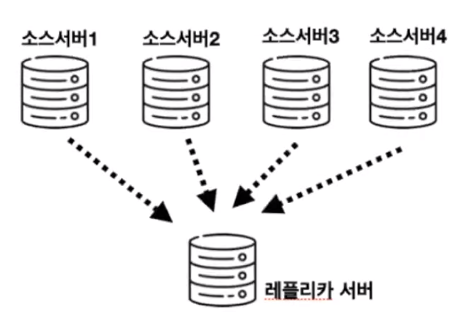
5. 멀티 소스 복제
구성: 소스 서버 n대, 레플리카 서버 1대
각각의 소스 서버가 다른 데이터를 가지고 하나의 레플리카 서버에 통합하는 방식이다.
때문에 데이터 분석 시 데이터를 한 번에 모아서 분석할 때 사용된다.
출처
https://youtube.com/watch?v=NPVJQz_YF2A&si=EnSIkaIECMiOmarE
https://www.coovil.net/db-replication/
https://nesoy.github.io/articles/2018-02/Database-Replication